
An AMD patent has surfaced that explains the implementation of a complex chiplet-based GPU with user-defined pipelines. Existing GPUs have a pre-defined datapath where different hardware components are used for the execution of the appropriate data types. The graphics processing device specified in the patent supports three different scheduling modes each suited for a different workload. In the below figure, you can see the basic setup of the proposed GPU:
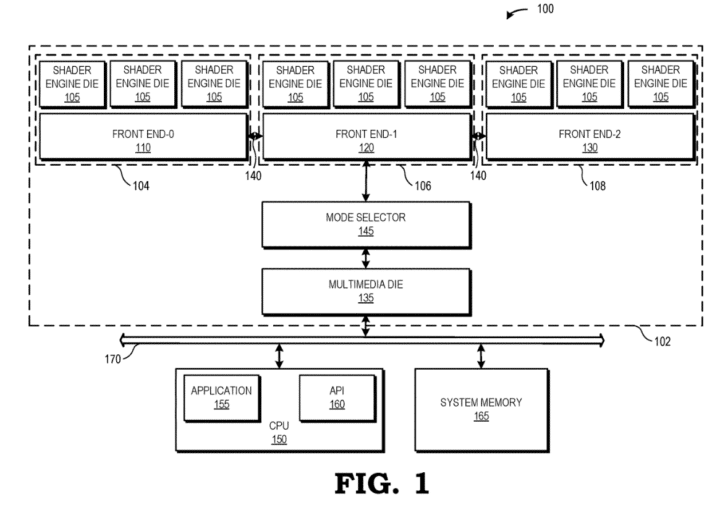
Here you’ve got three shader clusters each with three shader engine dies and a front-end scheduler die. Each cluster can be thought of as an independent GPU capable of executing/rendering its assigned work. The Navi 31 GPU powering the Radeon RX 7900 XTX consists of six shader engines, each packing 8 CUs or 512 cores. In this case, the three different modes alter the scheduler or command processor of the shader clusters.


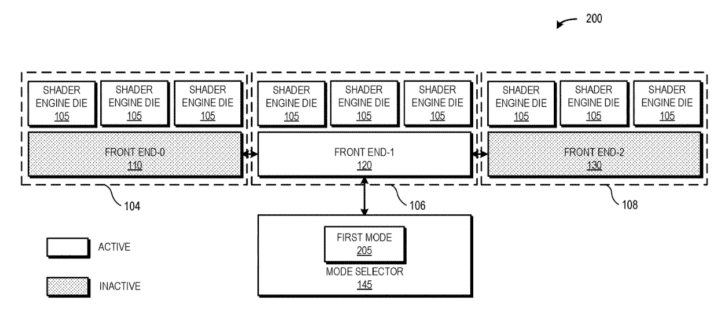
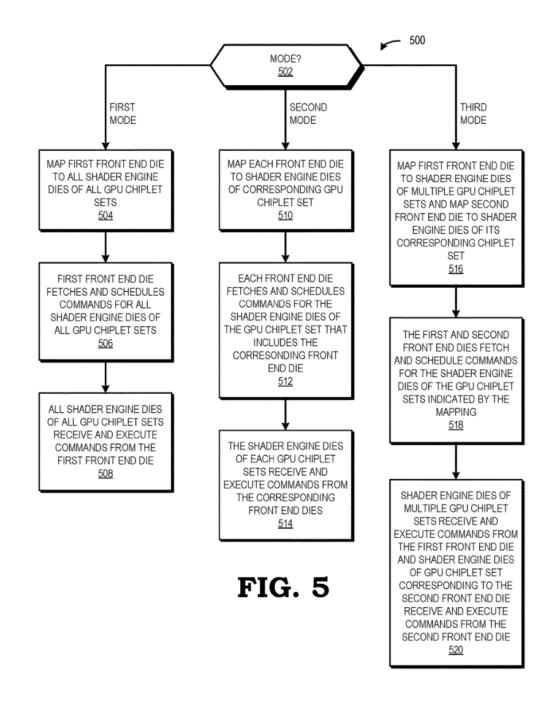
The first mode relies on a single front-end die which is assigned all three shader clusters and handles the work fetching, dispatch, and scheduling for the entire MCM GPU. This would be the simplest configuration of such a device with one single front-end die and several shader engine dies. The primary drawback would be the latency penalty and high bandwidth requirement involved in the communication with the (farther apart) shader dies. This can be avoided by using a faster interconnect and including a high-speed cache.
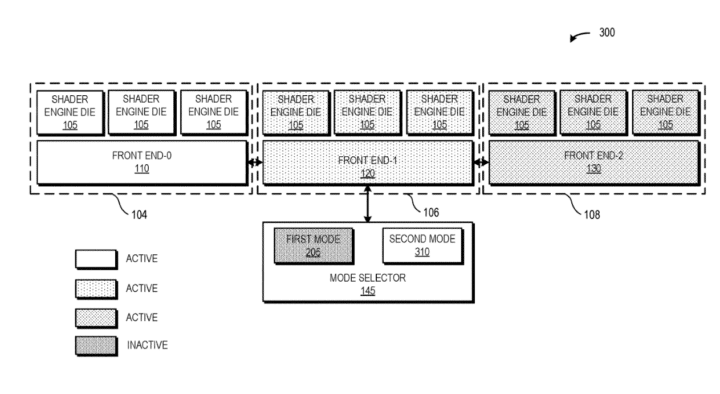
The second mode leverages a more parallel approach. Each shader cluster is managed by its corresponding front-end unit, dividing the scheduling work evenly between the three clusters. This would ensure higher utilization, but depending on the work division methodology, would require a close sync between the clusters. We’re most likely to see a similar configuration on the Radeon RX 9900 XTX or whichever GPU uses multiple shader dies.
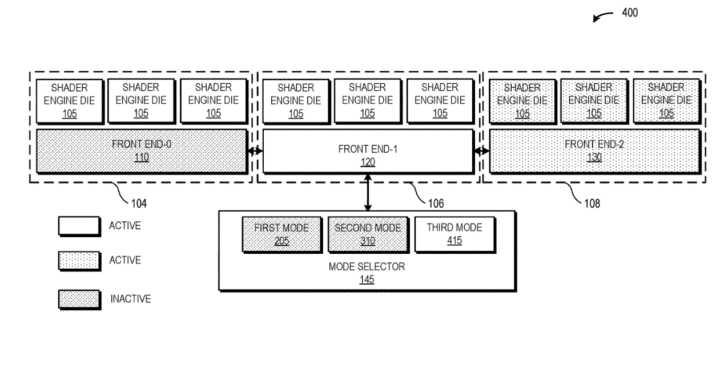
The third mode is a mix of the first two modes. Here, the central front end manages the work scheduling of its corresponding shader cluster as well as one of the other two clusters. The third remaining cluster is managed by its respective front end. I suppose this pipeline would be efficient in workloads that aren’t front-end bound and tend to leave the schedulers idle.
The use of different datapaths or pipelines for different workloads is an interesting concept, and will certainly be explored by chipmakers (if they haven’t already). However, a gaming GPU will have to be simpler. You don’t want much off-die data movement as that induces a heavy latency penalty, while also increasing power consumption. I wouldn’t expect more than two compute dies for the Radeon RX 9900 XTX (RDNA 5 flagship).
Further reading:



