
The fifth iteration of AMD’s Zen core architecture is set to launch later this month. Zen 5 marks nearly seven years of Ryzen processors, starting with the release of Zen in 2017. Since then, we’ve gotten Zen+, Zen 2, Zen 3, and Zen 4 at the heart of the Ryzen 2000, 3000, 5000, and 7000 series CPUs. The Zen 5 core powering the Ryzen 9000 lineup is the largest architectural overhaul of the frontend design, making it wider, faster, and more efficient than ever. Here’s a look at the five iterations of Zen.
AMD Zen vs Zen 2 vs Zen 3 vs Zen 4 vs Zen 5: CPU Frontend
The Branch Predictor and I-Cache
At the top, we’ve got the branch predictor, controlling the instruction flow like a ship’s navigator:


if condition
{dosomething}
else
{dosomethingelse}
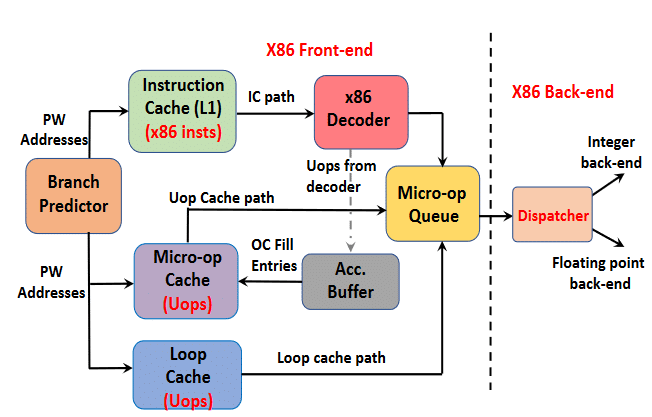
- It predicts whether the next instruction is a branch, and if yes, then what kind (conditional/unconditional).
- Branches are usually “if/else” conditional or unconditional (always branches).
- The next step is to calculate the address of the instruction (usually in the cache).
- The branch target buffer (BTB) is instrumental here. It contains a history of the last n branches (taken or not) and the destination address (PC) of the instructions.
- The branch predictor allows CPUs to continue executing even before the location of the next instruction is generated. This is called out-of-order execution.

- The Zen core architecture uses a Hash Perceptron branch predictor which uses a 3-level BTB.
- The branch predictor on Zen and Zen 2 stores up to 2 branches per BTB entry.
- The L0 BTB holds 4 forward and 4 backward-taken branches. The L1 BTB has 256 entries, while L2 has 4096.
- There’s also an Indirect Target Array with 1024 entries for indirect targets.
- The 64 KB L1I cache is paired with an 8-entry L0, 64-entry L1, and 512-entry L2 TLB.
- Zen 2 uses an L1 Hashed Perceptron and an L2 TAGE predictor.
- The L0 BTB holds 8 forward and 8 backward-taken branches. The L1 BTB has 512, while the L2 BTB has 7168 entries.
- The ITA is doubled with 1024 entries.
- The L1I cache is 32 KB with a 64-entry L1 and 512-entry L2 TLB.
- Zen 3 improves branch prediction accuracy and bandwidth, with a lower mispredict penalty. Most taken branches have a zero-bubble penalty (doesn’t stall the pipeline).
- The L1 BTB holds up to 1024, and the L2 BTB holds up to 6.5K entries.
- The ITA is expanded by 50% to 1536 entries.
- Zen 4 is capable of 2 taken branches per cycle.
- The L1 BTB can hold up to 1536, and the L2 BTB has 7168 entries.
- The ITA is expanded to roughly 3K entries.
- Zen 5 can do up to 2 taken and 2 ahead branches.
- The L1I cache size is unchanged, but it can fetch up to 32B x2 (previously 32B) of data from the L2 cache per cycle.
The Decoders, Op-Cache, and Op-Queue
The decoders take the instructions (complex) from the instruction cache, via the instruction queue, and break them down into simpler micro-ops. These are passed to the micro-op queue and also stored in the op cache. Micro-ops in the micro-op queue and dispatched to the execution backend.
Decoders are quite power-intensive, so making the op-cache more efficient and accurate is key. Instructions cached in the op-cache allow the front end to bypass the decoders, improving throughput and efficiency.
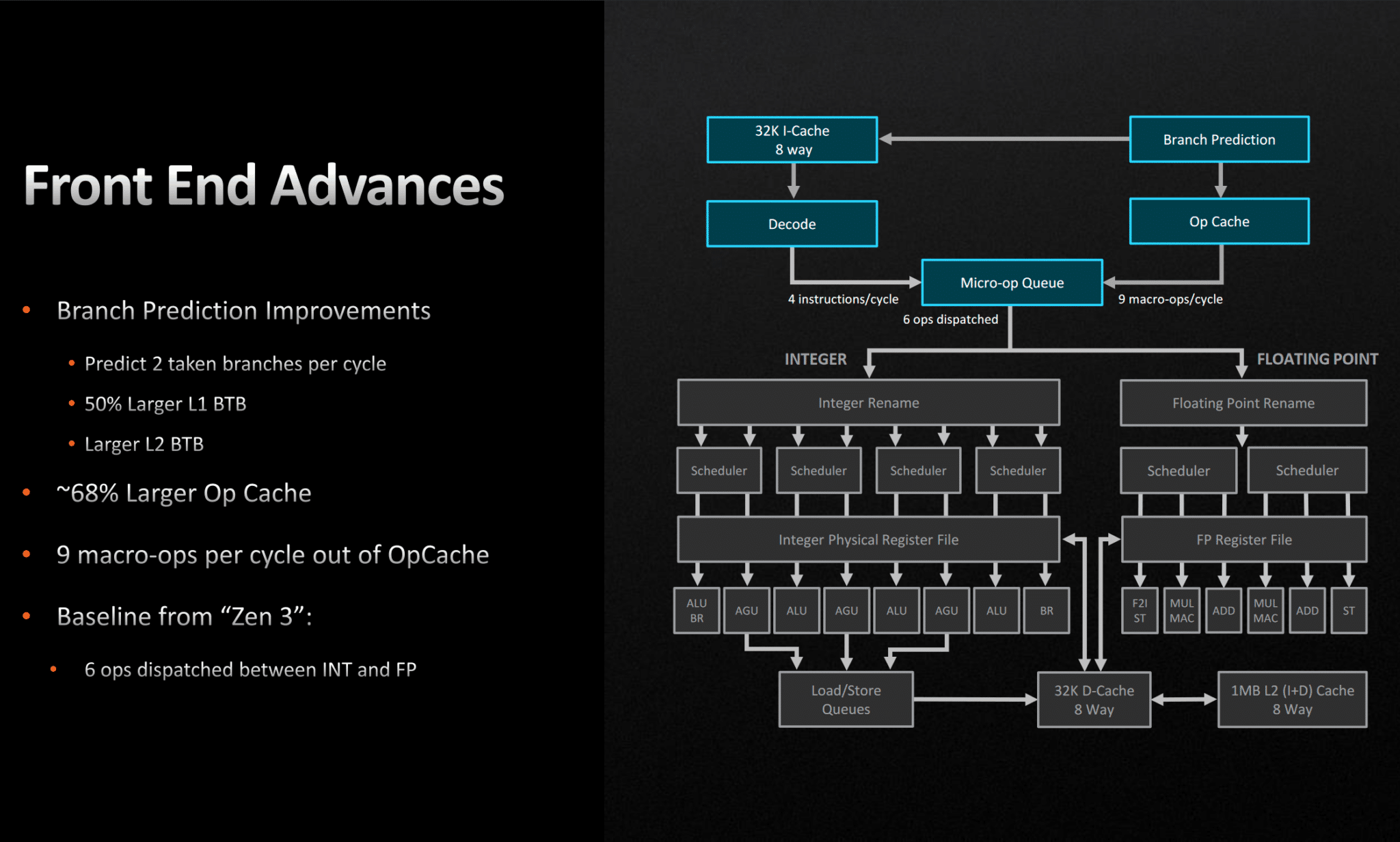
- The Zen core uses a 4-wide decoder, capable of decoding four instructions per cycle.
- It is fed by a 20 x16B instruction queue, remitting up to four instructions to the decoders.
- The op-cache has 2048 entries and can send up to 8 micro-ops to the op queue.
- The micro-op queue has 72 entries and gets 8 or 4 micro-ops from either the op-cache or the decoders.
- A maximum of 6 micro-ops are dispatched to the integer/floating point backends.
- Zen 2 doubles the size of the op-cache to 4096 entries.
- Zen 3 increases the instruction queue to 24 x16B.
- Zen 4 increases the op-cache capacity to 6.75K entries, making it capable of supplying up to 9 micro-ops to the micro-op queue.
- Zen 5 makes drastic changes to the decoders.
- It features 2x 4-wide decoders, capable of transmitting up to 4 micro-ops each.
- The decoders are fed by a dual-ported instruction fetch.
- The micro-op cache has been reduced to 6K, but it’s capable of supplying up to 12 (6×2) micro-ops to the micro-op queue.
- The dispatch has been expanded to 8-wide, capable of sending 8 micro-ops to the execution backend.
- When SMT is enabled, each thread gets one 4-wide decoder.

ROB, Schedulers, and Registers
The Reorder Buffer or the ROB is a critical component of out-of-order processors. It ensures that instructions are written to the registers per their initial order. It feeds the schedulers that hold instructions and their operands per the program sequence. When the operands for a particular set of scheduled instructions are available, they are sent to the execution units for execution.
Register Renaming is another critical part of OoO execution. If two or more instructions rely on the same memory location (register) but are independent of one another, the processor uses logical registers to create different variants of it. The renamed registers are executed in parallel without causing any data hazards.

- The Zen core can hold 192 entries in its ROB with separate integer and floating point scheduler/registers and execution units.
- The FP rename is 6-wide, while the integer rename is 4-wide.
- It has 4x 14-entry integer and 2x 14-entry AGU schedulers.
- The FP scheduling queue has 96 entries.
- The integer register file has 168, while the floating point file has 160 entries.
- Zen 2 increases the ROB size to 224 and doubles the floating point data paths.
- It has 4x 16-entry integer and 1x 28-entry AGU scheduler.
- The integer register file has been increased to 180.
- The FP side has a 64-entry non-scheduling and 36 entries in the scheduler buffer.
- Zen 3 has a slightly wider ROB with 256 entries.
- 4x 24-entry integer+AGU schedulers.
- The FP side has a 64-entry scheduling and 2x 32-entry scheduling queues.
- The integer register file is increased to 192.
- Zen 4 increases the ROB size to 320.
- The integer register file features 224 entries, while the FP side has 192x 512-bit registers.
- There’s also a 68-entry AVX512 mask register file.
- Zen 5 increases the ROB size to 448 entries.
- The FP rename is 6-wide, while the integer rename is 8-wide.
- The FP side has 3x 32-entry schedulers and a 96-entry non-scheduling queue.
- The integer register file has 240 (64b) entries, while the FP side has 384 (512b) entries.

Execution Units and Memory Subsystem
The Execution Units perform various arithmetic, floating point, address generation, load-store, or branch-related calculations as per the program-order to obtain the final result. Modern CPU cores feature multiple independent execution paths specialized for specific instructions, such as FADD, FMUL, FMA, ALU, AGU, LD/ST, etc. The results obtained are written to the registers or redirected to the retire queue.
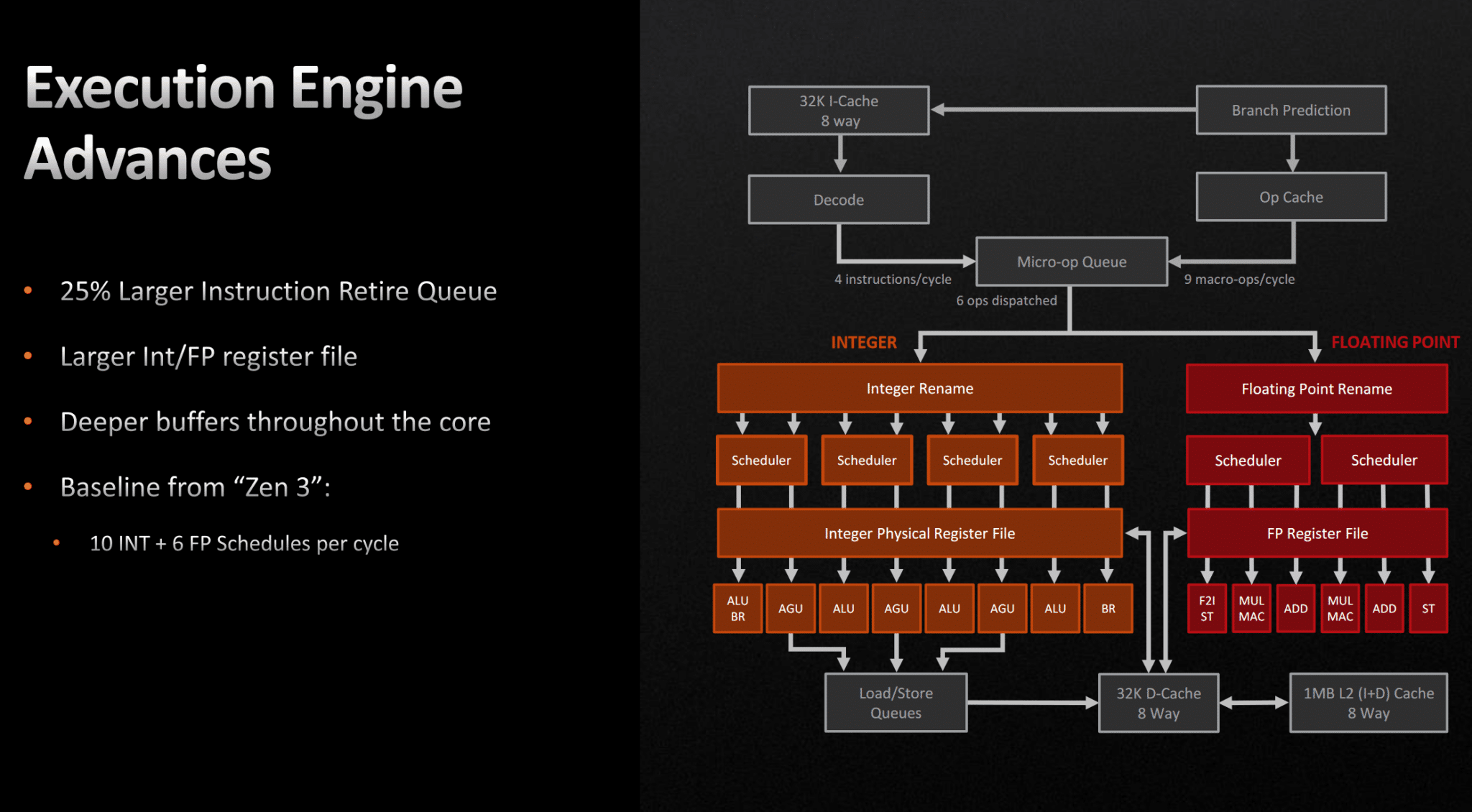
- The Zen core features ten execution ports.
- The integer side has 4x ALU and 2x AGU ports.
- The FP side has 2x FMUL/FMA and 2x FADD execution units (128-bit).
- The load buffer has 72, and the store buffer has 44 entries.
- Zen is capable of 2x 128-bit loads and 1x 32B stores.
- It is backed by a 32 KB 8-way data cache and a 512 KB L2 cache.
- Zen 2 has eleven execution ports.
- The integer side has 4x ALU and 3x AGU ports.
- The FP side has 2x FMA and 2x FADD units (256-bit).
- It has a store queue with 48 entries.
- The load/store bandwidth is increased to 256-bit per cycle.
- Zen 3 has fourteen execution ports.
- The integer side has 4x ALU, 3x AGU, and 1x branch execution units.
- The FP side has 2x FMA, 2x FADD, and 2x store units.
- The store queue has 64, while the load queue has 116 entries.
- The load bandwidth is up to 3x 64-bit (or 2x 256-bit) and store to 2x 64-bit (or 1x 256-bit).
- Zen 4 retains the 14-wide execution backend.
- Zen 4 is capable of AVX512 instructions by double pumping the 256-bit wide floating-point units.
- The L2 cache is increased to 1 MB 8-way.
- Zen 5 has sixteen execution ports.
- The integer execute consists of 6x ALU ports, and 4x AGU ports.
- The FP side has 2x FMUL, 2x FADD, and 2x intD/StD execution ports.
- Zen 5 supports native AVX512 execution using 512b datapaths.
- It is capable of 4x 64-bit or 2x 256-bit stores and 2x 128-bit/256-bit or 1x 512-bit stores per cycle.
- It also increases the L1 Data Cache to 48 KB 12-way, with 4 reads and 2 writes per cycle.
- The L1 to L2/FP bandwidth has been doubled to 64 bytes per cycle.

AMD Zen 1 vs Zen 2 vs Zen 3 vs Zen 4 vs Zen 5: Front End Summary
| Zen | Zen 2 | Zen 3 | Zen 4 | Zen 5 | |
|---|---|---|---|---|---|
| L1I Cache | 64 KB | 32 KB | 32 KB | 32 KB | 32 KB |
| ITLB entries | 64 L1/512 L2 | 64 L1/512 L2 | 64 L1/512 L2 | 64 L1/512 L2 | 64 L1/512 L2 |
| BTB entries | 256 L1/4K L2 | 512 L1/7K L2 | 1024 L1/6.5K L2 | 1536 L1/7K L2 | ? |
| Instruction Q | 20x 16B | 20x 16B | 24x 16B | 24x 16B | ? |
| Decoder width | 4-wide | 4-wide | 4-wide | 4-wide | 2x 4-wide |
| Micro-op Cache entries | 2K | 4K | 4K | 6.75K | 6K |
| Op Cache bw (uops) | 8 | 8 | 8 | 9 | 2x 6 |
| Dispatch (uops) | 6 | 6 | 6 | 6 | 8 |
AMD Zen 1 vs Zen 2 vs Zen 3 vs Zen 4 vs Zen 5: Back End Summary
| Zen | Zen 2 | Zen 3 | Zen 4 | Zen 5 | |
|---|---|---|---|---|---|
| ROB entries | 192 | 224 | 256 | 320 | 448 |
| INT Scheduler | 6x 14 entry | 4x 16 entry (1x 28 entry AGU) | 4x 24 entry | 4x 24 entry | 88 entry (56 AGU) |
| FP Scheduler | 96 entry | 36 entry | 2x 32 entry | 2x 32 entry | 3x 32 entry |
| INT Registers | 168 entries | 180 entries | 192 entries | 224 entries | 240 entries |
| FP Registers | 160 entries | 160 entries | 160 entries | 192x 512-bit (68 512b mask) | 384x 512-bit |
| ALU Ports | 4 | 4 | 4 (+1 BR) | 4 (+1 BR) | 6 |
| AGU Ports | 2 | 3 | 3 | 3 | 4 |
| FP Ports | 4 (128b) | 4 (256b) | 4 | 4 (+2 F2I) | 4 (+2 StD IntD) |
| LD/ST Q | 72/44 entries | 72/48 entries | 116/64 entries | 136/64 entries | ? |
| LD/ST bw | 32B/2x 128b | 2x 256b | 2x 256b/256b | 2x 256b/256b | 2x 512b/512b |
| L1D | 32 KB | 32 KB | 32 KB | 32 KB | 48 KB |
| L2 | 512 KB | 512 KB | 512 KB | 1 MB | 1 MB |
Further reading:
Intel Golden Cove vs Raptor Cove vs Redwood Cove vs Lion Cove: Intel’s P-Core Architectures Compared



