
Intel has shipped four performance (P) cores in the last ten years, with the latest hitting notebook PCs a few quarters ago. Skylake landed in 2015, followed by several refreshes and a premature Cannon Lake launch that resulted in even more rebrands. Ice Lake (Sunny Cove) was launched in H2 2019 (on a limited scale), followed by Tiger Lake and Alder Lake, featuring the Golden Cove core architecture in Q4 2021. Redwood Cove debuted with Meteor Lake last year, paving the way for Arrow Lake and the corresponding Lion Cove core architecture.


Intel Skylake: Kaby Lake, Coffee Lake, Whiskey Lake, Comet Lake
Skylake remains Intel’s most employed core architecture, powering the 6th, 7th, 8th, 9th, and 10th Gen lineups. Starting from the top of the front end, we’ve got a 32KB L1 instruction cache and Branch Prediction Unit (BPU).
- The Branch Prediction Unit is like the processor’s driver, controlling the flow of instructions, by predicting if the next instruction is a branch or not, and of what kind (conditional/unconditional).
- The first step is to calculate if the instruction is a branch. And if yes, will it be taken? If yes again, the address of the next instruction needs to be calculated (usually in the L1I).
- The history of the last n branches (yes or no) and the destination address (PC) are stored in the Branch Target Buffer (BTB). The BTB is used to validate the branches post-execution and as a guide to determine whether future branches will be taken, and their address.
- Like CPU cache, BTBs have multiple levels, each with its branch predictor.
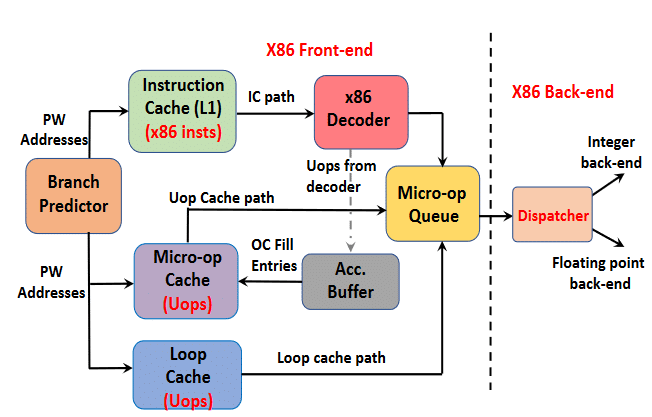
Front-end
Skylake has a two-step branch prediction, with 128 (L0) and 4096 (L1) entry Branch Target Buffers. Larger BTBs allow for extended program tracking (PC), improving accuracy. Modern branch predictors have an accuracy of well over 90%.
- The predictions (PWs) generated by the BPU are sent to the instruction cache (L1I) and the micro-op cache. The L1I cache sends these instructions to the instruction fetch/pre-decode window, instruction queue, and the decoders.
- The decoders break down the macro-ops into micro-ops, sending them to the micro-op queue and the op cache.
- The micro-op cache stores frequently used micro-ops and can bypass the decoders if the same instructions are needed again. This improves power efficiency and performance. Larger op caches usually result in reduced usage of the decoder stage, thereby speeding up the pipeline.

Intel Skylake features a 16-byte (per cycle) instruction fetch and a 50-entry instruction queue, followed by a 4-way decoder consisting of three simple and one complex decoder capable of breaking down long macro-instructions into (up to) 4 micro-instructions. The micro-op cache holds 1536 entries, feeding a 128-entry (64×2) micro-op queue with up to 6 micro-ops per cycle.
- The Allocation Queue feeds the core backend, starting with the Reorder Buffer.
- The Reorder Buffer or the ROB is a critical component of out-of-order processors. It ensures that instructions are written to the registers per their initial order. It is a circular queue (FIFO) with head and tail pointers.
- Register Renaming is another critical part of OoO execution. If two or more instructions rely on the same memory location (register) but are independent of one another, the processor uses logical registers to create different variants of it.

- These renamed registers are then executed in parallel without causing any data hazards.

- When renaming, instructions are assigned an entry at the tail of the reorder buffer (ROB) which becomes the name of or points to the result register. As instructions reach the head of the ROB, their value is stored in the integer/floating point register file.
- If all the required operands for an instruction are available (ready for execution), it is sent to the Reservation Station (Unified Scheduler).
- The Scheduler holds the instructions and their operands per the program sequence. If the operand isn’t available, the RS will monitor the Common Data Bus (connecting the EUs to the ROB and RS) for it. When the operand is available, it’s cached by the RS, and the instruction is executed.
- After execution, instructions are removed from the Reservation Station but remain in the Reorder Buffer.
- Instructions at the head of the ROB are committed once they are executed, thereby freeing the ROB and its registers.
- Skylake also features a 48-entry Branch Order Buffer (BOB) next to the ROB. It keeps track of the last known valid state and helps restore the pipeline to an earlier state after an incorrect branch.
Back-end
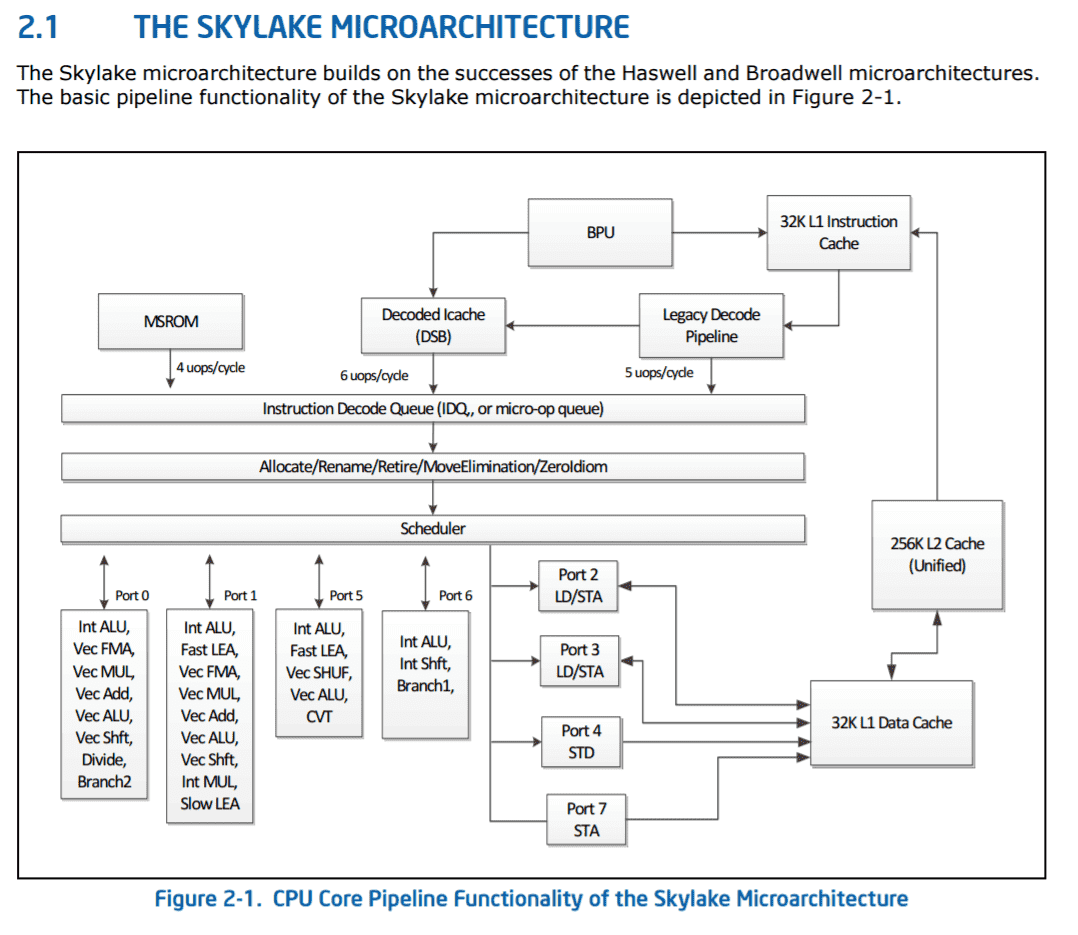
Intel’s Skylake core dispatches 6 micro-ops to the backend from the allocation queue, feeding the 224-entry Reorder Buffer and the Reservation Station. The RS or Unified Scheduler can hold 97 entries. There are also the physical registers used in register renaming, 180 integer, and 168 floating point registers.
Skylake has four execution ports and six load/store ports. The ALUs are 256-bit, with a 58-entry scheduler. The AGU scheduler has 39 entries, and a bandwidth of 64 KB/s for loads and 32 KB/s for stores. The load/store queue holds 72/56 entries. The L1 Data cache is 32 KB (8-way), and the L2 cache is 256 KB (4-way).
Intel Sunny Cove, Cypress Cove, Willow Cove: Ice Lake, Rocket Lake, Tiger Lake
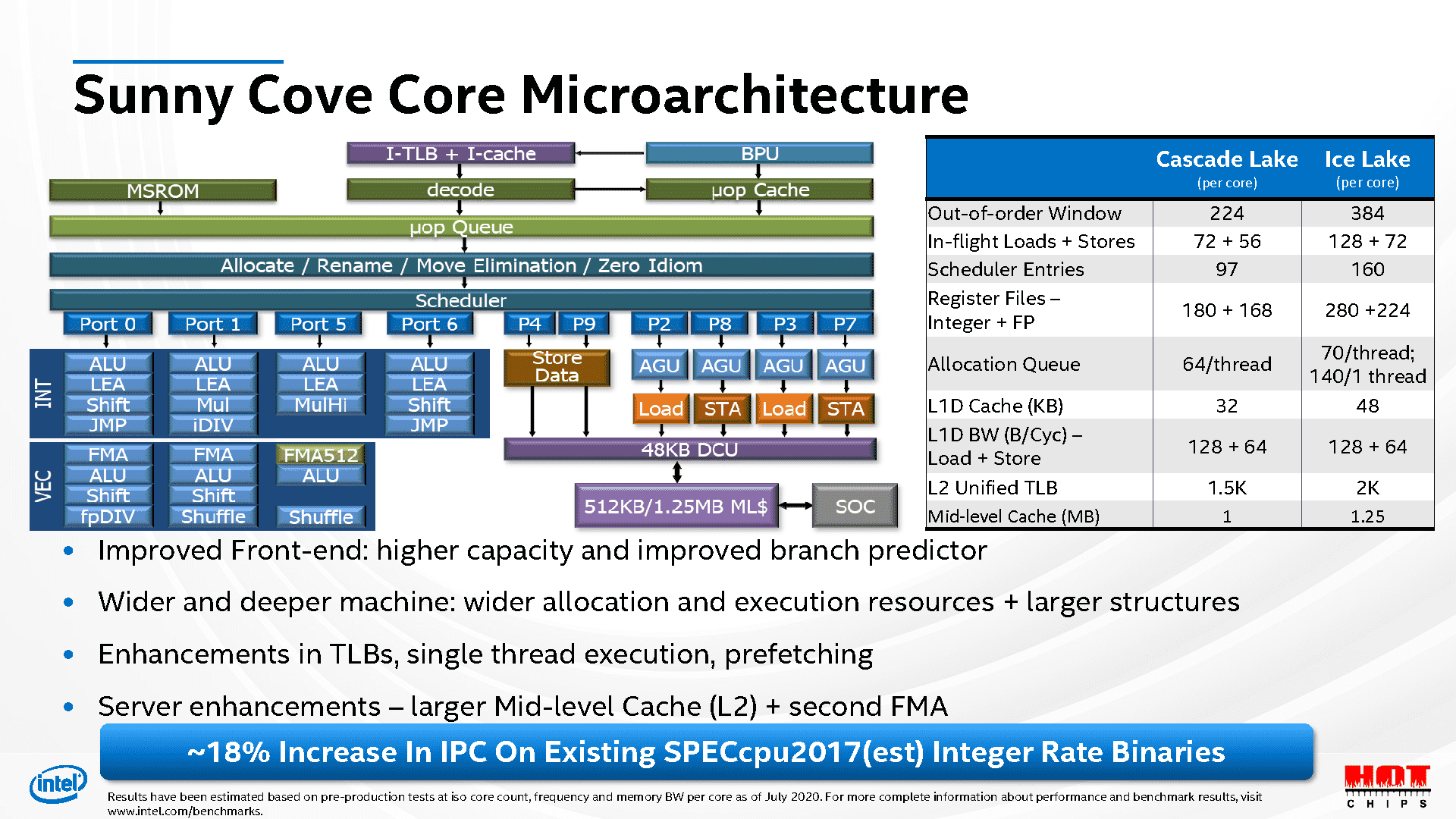
Sunny Cove was Intel’s first 10nm (FinFET) core architecture released in Q3 2019. And no, we won’t count Cannon Lake. It was a well-rounded upgrade to a dated core design, from the dispatch window to the ROB, registers, and schedulers.
Front-end
- The L0 BTB was doubled from 128 to 256, and the L1 BTB was increased from 4K to 5K.
- The micro-op cache was expanded from 1536 to 2304 entries.
- The micro-op queue was increased from 128 to 140 entries.
- The dispatch bandwidth was increased from 4 to 5 micro-ops.
Back-end
- The Reorder Buffer was expanded from 224 to 352 entries.
- The Branch Order Buffer was increased from 64 to 96 entries.
- The integer registers were increased from 180 to 280. The FP register count went up from 168 to 224.
- The ALU scheduler was expanded from 58 to 80.
- The L1D increased from 32KB to 48KB, while the L2 expanded from 256KB (1.5K TLB) to 1280KB (2K TLB).
- Two execution ports got wider FMA/ALU units: 256-bit->512-bit.
- The AGU schedulers were beefed up to 34 and 46 (previously 39).
- The Store Data/AGU ports were increased from 1/3 to 2/4.
- The Load/Store queues went up from 72/56 to 128/72.
- The Load/Store bandwidth was doubled from 64KB/32KB to 128KB/64KB.
Intel Golden Cove, Raptor Cove: Alder Lake, Raptor Lake
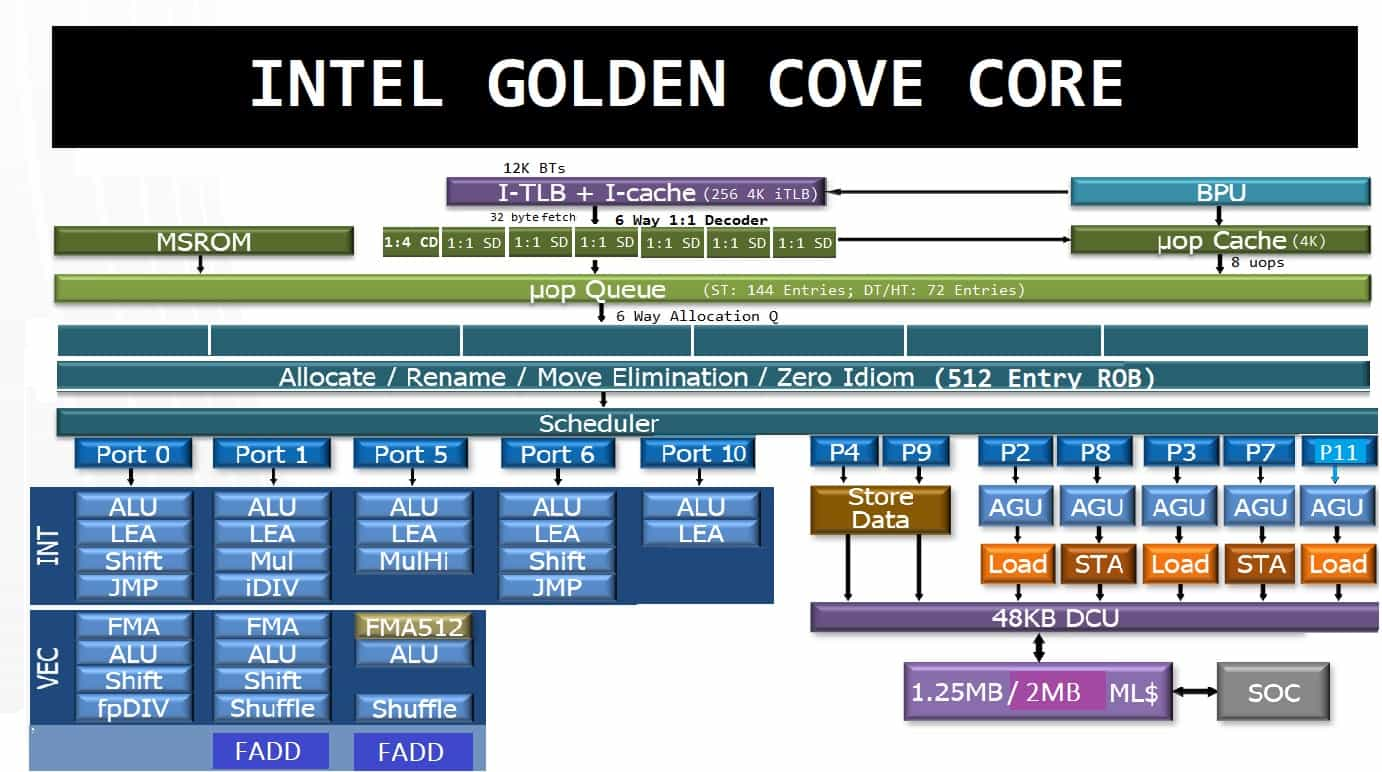
The Golden Cove core architecture based on the 10nm ESF process was introduced with Alder Lake-S in November 2021. While Sunny Cove focused on the back-end, Golden Cove widened the front-end and the branch predictor.
Front-End
- The ITLB (Instruction TLB) was doubled from 128 to 256 entries.
- A third stage L2 BTB with 12K entries was added, and L1 BTB grew from 5K to 6K entries.
- The instruction fetch bandwidth was doubled from 16 bytes to 32 bytes per cycle.
- The decoder was widened from 4 to 6-way.
- The micro-op cache was expanded from 2304 to 4096 entries.
- The micro-op cache bandwidth increased from 6 to 8 uops.
- The uop queue increased from 140 to 144.
- The dispatch bandwidth increased from 5 to 6 uops.
Back-end
- The Reorder buffer was expanded from 352 to 512 entries.
- The Branch Target Buffer grew from 96 to 128 entries.
- The FP register file was increased from 224 to 332.
- The ALU scheduler was expanded from 80 to 97 entries, and a fifth execution port was added.
- A FADD vector unit was added to the ports 1 & 5.
- The load/store schedulers were consolidated to 70/38 entries.
- The load/store queue was widened from 128/72 to 192/114 entries.
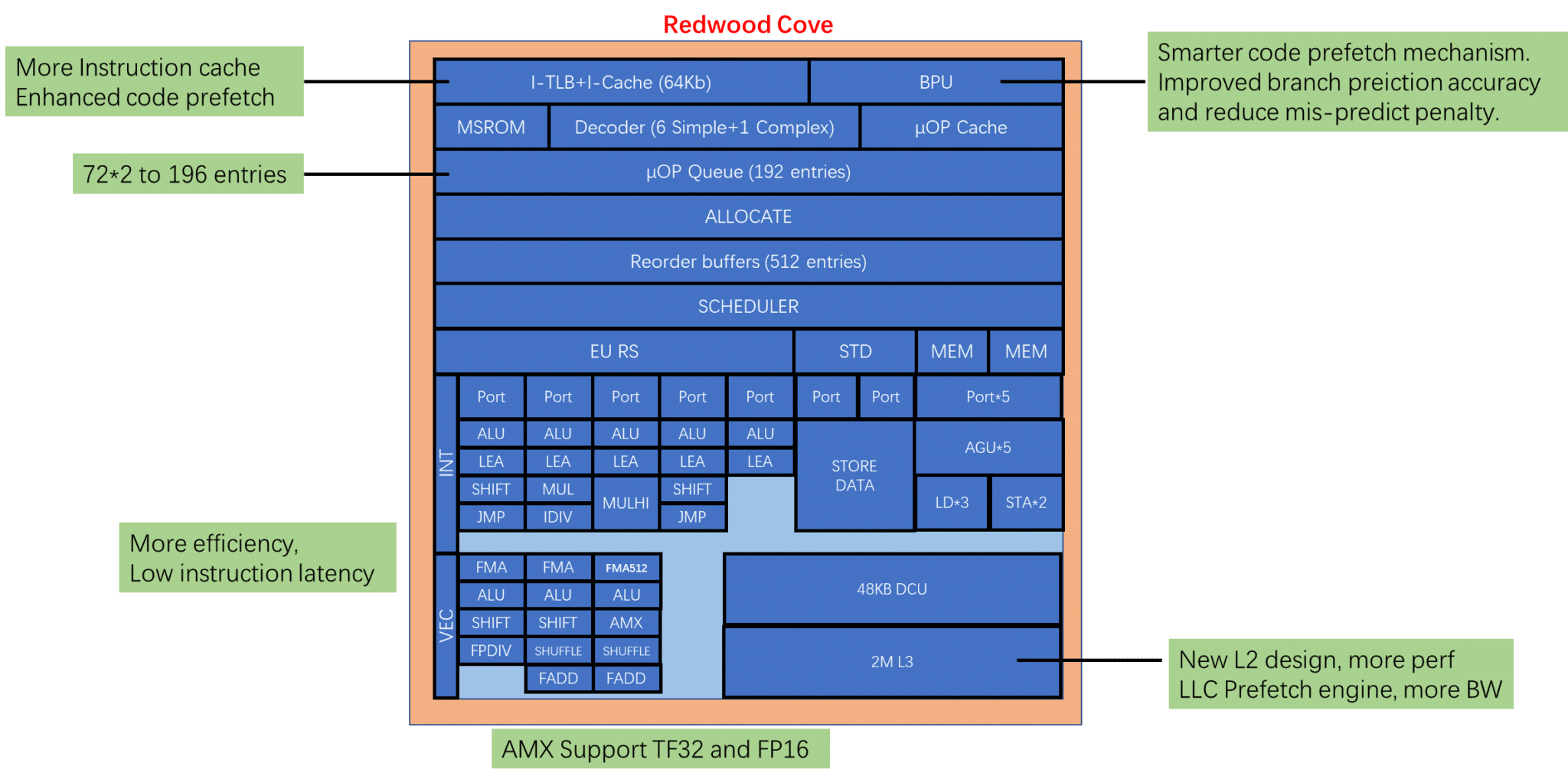
Intel Redwood Cove: Meteor Lake “Core Ultra”
Redwood Cove leverages the Intel 4 process node and makes slight modifications to the Golden Cove core architecture. You can think of it as a “Tick,” a node shrink with minimal changes to the microarchitecture.
- The I-Cache is up from 32KB to 64KB.
- The micro-op queue has been increased from 144 to 192 entries.
- Instruction execution latency is lower.
- “Smarter” prefetch and improved BPU.
- Support for AMX instructions.
Intel Lion Cove: Arrow Lake, Lunar Lake “Core Ultra 200”
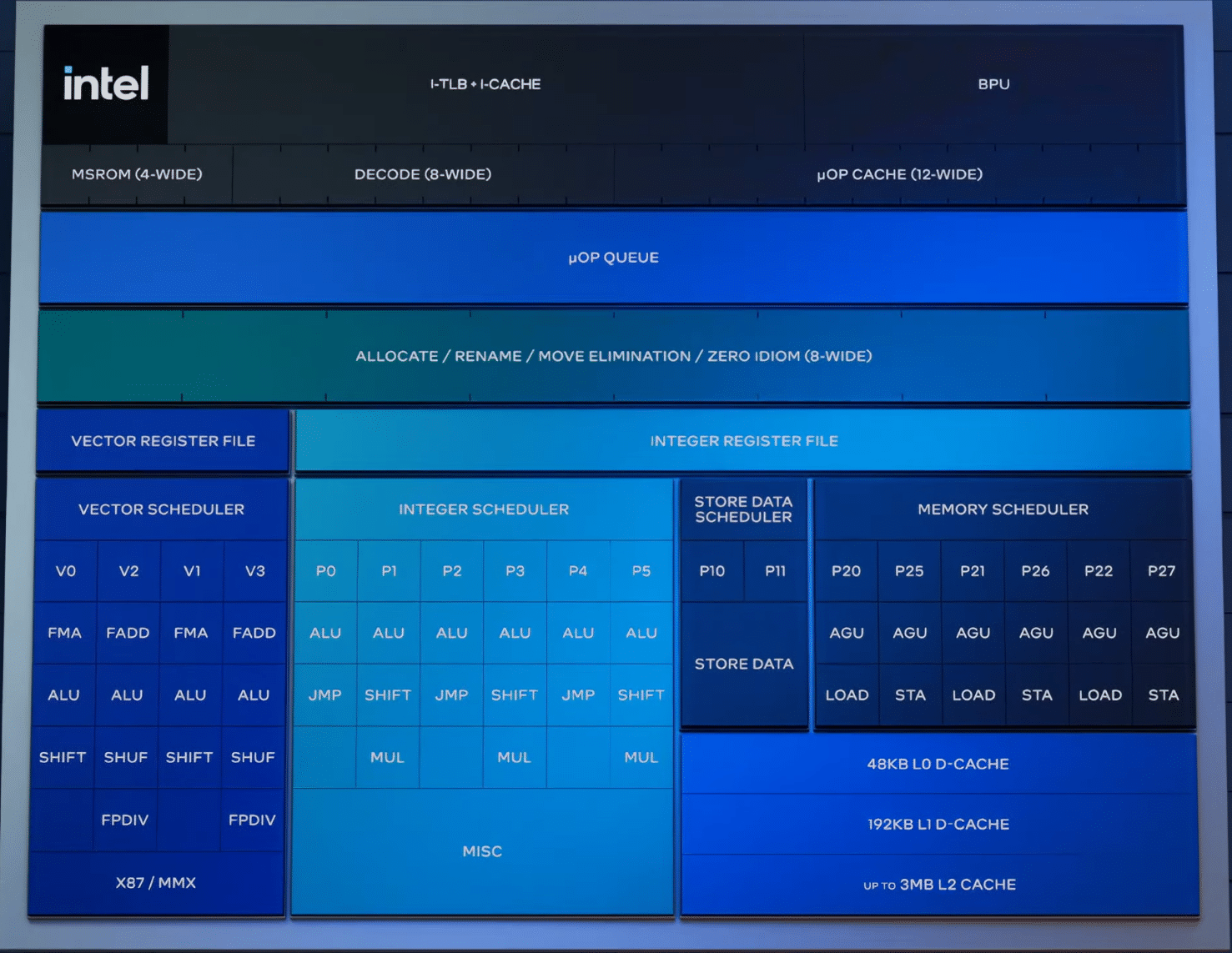
Lion Cove is Intel’s upcoming P-core architecture powering the Arrow Lake “Core Ultra 200” and Lunar Lake “Core Ultra 200V” processors. It will leverage TSMC’s 3nm “N3B” and the Intel 20A process nodes. Intel has confirmed the following architectural upgrades.
Front-end
An 8x larger prediction block: Without revealing any solid details, Intel claims that Lion Cove features a much bigger BPU than Golden and Redwood Cove. This probably means larger BTBs, but by how much? We’ll have to wait and see.
Wider fetch, decode, and uop cache: Lion Cove doubles the fetch bandwidth from 32KB to 64KB. The instruction decoder is 8-wide (previously 6-wide), uop cache is 12-wide (previously 8) or 5.25K entries (up from 4096), and the MSROM is 4-wide (up from 3).
Higher op-cache bandwidth and queue (ILQ): The op-cache can now transmit up to 12 uops (up from 8) to an expanded uop queue of 192 entries.
Back-end
Wider Allocate, Retire, and Reorder: The rename/dispatch buffer has been expanded to hold 8 instructions (up from 6), and the retire throughput is up from 8 to 12 instructions per cycle. Accordingly, the Reorder buffer has been buffed up from 512 to 576 entries.
Separate Integer and Floating Point Execute: Lion Cove splits the integer and floating point execution with separate schedulers and register files:
- On the integer side, the ALUs, JMP, and SHIFT units have been increased from 5->6, 2->3, and 2->3. Two additional MUL units have also been added (previously 1).
- Vector execution consists of 4x 256-bit ALUs (up from 3), 2x 256-bit FMAs (4 cycle latency), and 2 FP dividers (up from 1) with a higher throughput (256-bit) and lower latency.
- The overall execution port count has been increased from 12 to 18.

Cache and Memory Subsystem: A third STA AGU unit brings the STA count on par with load AGUs (three each), with two store data pipes. The data cache hierarchy has been revised, with three levels (previously 2) and a deeper TLD (96->128 pages):
- The L0 cache packs 48KB with a 4-cycle latency, followed by a 192KB L1 with a 9-cycle latency, and a larger 3MB L2 with a 17-cycle latency.
- Redwood Cove had a much higher 16-cycle latency for the second-level L2 cache, nearly as much as the 3MB L2 on Lion Cove.

Intel Skylake vs Sunny Cove vs Golden Cove vs Raptor Cove vs Redwood Cove vs Lion Cove: Core Architecture Summary
Front-end
| Front-end | Skylake | Sunny Cove | Golden Cove | Redwood Cove | Lion Cove |
|---|---|---|---|---|---|
| I-Cache | 32 KB | 32 KB | 32 KB | 64 KB | 64 KB |
| ITLB | 128 | 128 | 256 | 256? | 256? |
| Branch Target Buffer | 128/4K | 256/5K | 128/6K/12K | ? | ? |
| Instruction Fetch B/w | 16 Bytes | 16 Bytes | 32 Bytes | 32 Bytes | 128 Bytes |
| Instruction Queue | 50 | 50 | 50 | 50? | ? |
| Decoder | 4-way | 4-way | 6-way | 6-way | 8-way |
| Micro-op Cache | 1536 | 2304 | 4096 | 4096 | 5.25K |
| Micro-op Cache B/w | 6 | 6 | 8 | 8 | 12 |
| Micro-op Queue Width | 128 | 140 | 144 | 192 | 192 |
| Rename/Dispatch | 4 | 5 | 6 | 6 | 8 |
Back-end
| Back-end | Skylake | Sunny Cove | Golden Cove | Redwood Cove | Lion Cove |
|---|---|---|---|---|---|
| Reorder Buffer | 224 | 352 | 512 | 512 | 576 |
| Branch Order Buffer | 64 | 96 | 128 | 128 | ? |
| Retire B/w | 4 | 5 | 8 | 8 | 12 |
| Int Reg/FP Reg | 180/168 | 280/224 | 280/332 | 280/332 | ? |
| EU Scheduler | 58 | 80 | 97 | 97 | ? |
| Load Scheduler | 39 (shared) | 23 | 70 | 70 | ? |
| Store Scheduler | 39 (shared) | 23 + 34 SD | 38 | 38 | ? |
| Execution Ports | 4 | 4 | 5 | 5 | 10 |
| Store Data Ports | 1 | 2 | 2 | 2 | 2 |
| Load AGU | 2 | 2 | 3 | 3 | 3 |
| Store AGU | 1 | 2 | 2 | 2 | 3 |
| Load Queue | 72 | 128 | 192 | 192 | ? |
| Store Queue | 56 | 72 | 114 | 114 | ? |
| Load B/w | 64 Bytes | 128 Bytes | 96 Bytes | 128 Bytes | 128 Bytes |
| Store B/w | 32 Bytes | 64 Bytes | 64 Bytes | 64 Bytes | 64 Bytes? |
| L1D Cache | 32 KB | 48 KB | 48 KB | 48 KB | 48 KB/192 KB |
| DTLB | 64 | 64 | 96 | 96 | 128 |
| L2 Cache | 256 KB | 1280 KB | 1280 KB | 2 MB | 2.5 MB/3 MB |
| L2 TLB | 1536 | 2048 | 2048 | ? | ? |
Willow and Raptor Cove are omitted as they’re refreshes of Sunny and Golden Cove, respectively with increased L2 cache.


